icon
Update time
Jul 24, 2022 08:13 AM
Internal status
password
原创
故障表现
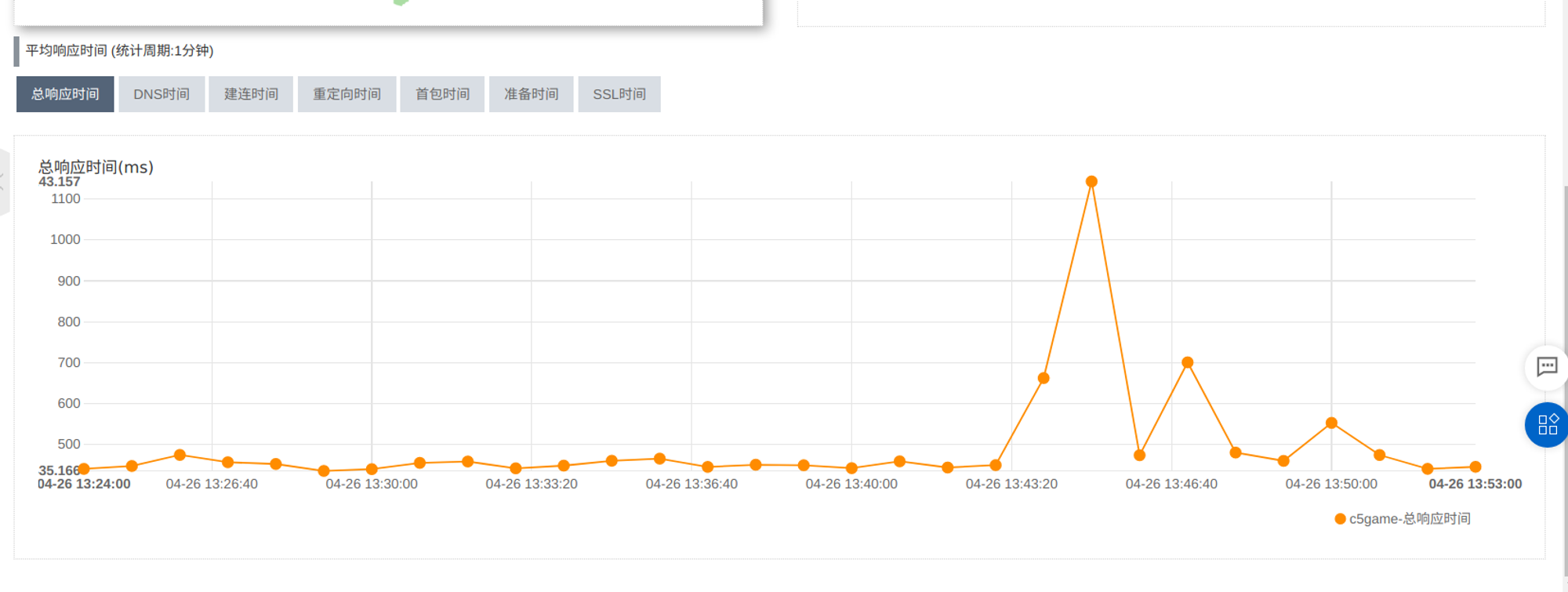
在重新发布交易服务的时候,网站出现访问延迟增长的情况
故障分析
排查清单
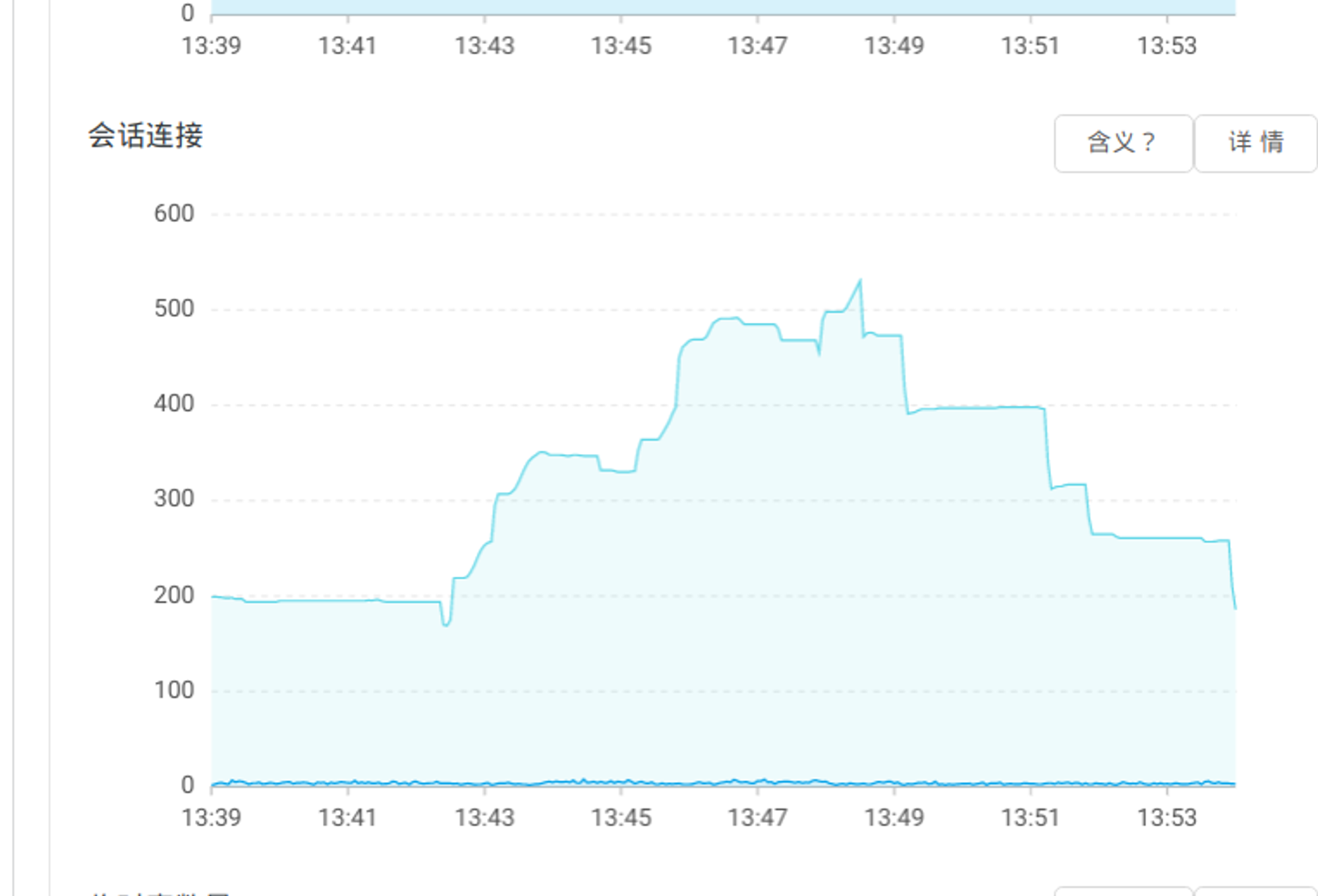
RDS数据库指标是否正常,CPU,内存正常,会话数激增
ES搜索服务是否正常,正常
REDIS服务是否正常,正常
确认基本方向,可能数据库连接配置存在问题
排查druid依赖版本问题
查看pom依赖,发现版本太老了,1.0.16的版本发布于2015年10月
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.0.16</version> </dependency>
进行升级测试,保险起见,升级到1.1.x系列的最新版本,发布于2020.9月,还有最新的1.2.x版本可能存在较大更新,没有尝试
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.24</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.24</version> </dependency>
本地测试正常,无兼容性修改
排查druid配置问题
生产环境配置如下
trade: datasource: #druid相关配置 druid: #监控统计拦截的filters filters: stat driverClassName: com.mysql.jdbc.Driver #配置基本属性 url: **** username: *** password: **** #配置初始化大小/最小/最大 initialSize: 50 minIdle: 10 maxActive: 300 #获取连接等待超时时间 maxWait: 60000 #间隔多久进行一次检测,检测需要关闭的空闲连接 timeBetweenEvictionRunsMillis: 60000 #一个连接在池中最小生存的时间 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 'x' testWhileIdle: true testOnBorrow: false testOnReturn: false #打开PSCache,并指定每个连接上PSCache的大小。oracle设为true,mysql设为false。分库分表较多推荐设置为false poolPreparedStatements: false maxPoolPreparedStatementPerConnectionSize: 20
查询druid配置最佳实践相关资料
得到的核心结论为:最大连接数 = ((核心数 * 2) + 有效磁盘数)
我们容器配置为初始化2核,SSD盘,根据理论公式,2核基本上为4线程,最大连接数为8即可
根据druid官方仓库的DruidDataSource配置 · alibaba/druid Wiki的说明,最大连接数并没有超过20
因此,做了一些更改
trade: datasource: #druid相关配置 druid: filters: stat driverClassName: com.mysql.jdbc.Driver url: jdbc:**** username: **** password: **** initialSize: 10 #由50改为10 minIdle: 10 maxActive: 20 #由300改为20 #获取连接等待超时时间,由60秒改为6秒 maxWait: 6000 #间隔多久进行一次检测,检测需要关闭的空闲连接 timeBetweenEvictionRunsMillis: 2000 #由60秒改为2秒,目的尽早释放连接 #一个连接在池中最小生存的时间 minEvictableIdleTimeMillis: 600000 validationQuery: SELECT 1 testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: false maxPoolPreparedStatementPerConnectionSize: 20 keepAlive: true # 增加keepAlive参数,保持连接 phyMaxUseCount: 1000 #新版本的druid新增的参数,针对分布式数据库的优化,每个连接使用此次数后就释放,让负载更加均衡
压测性能表现
通过调用一个多次查询数据库的接口进行测试
原来的配置
ab -n1000 -c40 https://xxxxx This is ApacheBench, Version 2.3 <$Revision: 1879490 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Completed 1000 requests Finished 1000 requests Server Software: Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256 Server Temp Key: X25519 253 bits Document Path: Document Length: 194 bytes Concurrency Level: 40 Time taken for tests: 6.032 seconds Complete requests: 1000 Failed requests: 0 Total transferred: 670000 bytes HTML transferred: 194000 bytes Requests per second: 165.78 [#/sec] (mean) Time per request: 241.288 [ms] (mean) Time per request: 6.032 [ms] (mean, across all concurrent requests) Transfer rate: 108.47 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 28 129 91.2 114 793 Processing: 22 84 69.3 65 537 Waiting: 22 84 69.2 64 537 Total: 55 214 139.1 181 1042 Percentage of the requests served within a certain time (ms) 50% 181 66% 214 75% 246 80% 266 90% 357 95% 522 98% 706 99% 769 100% 1042 (longest request)
升级druid版本和修改配置后的压测结果
调整配置后 ab -n1000 -c40 https://xxxx This is ApacheBench, Version 2.3 <$Revision: 1879490 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Completed 1000 requests Finished 1000 requests Server Software: Server Hostname: xxxx Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256 Server Temp Key: X25519 253 bits TLS Server Name: xxxx Document Path: 114&platformId=2 Document Length: 194 bytes Concurrency Level: 40 Time taken for tests: 3.611 seconds Complete requests: 1000 Failed requests: 0 Total transferred: 670000 bytes HTML transferred: 194000 bytes Requests per second: 276.95 [#/sec] (mean) Time per request: 144.430 [ms] (mean) Time per request: 3.611 [ms] (mean, across all concurrent requests) Transfer rate: 181.21 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 27 85 34.1 95 196 Processing: 22 52 15.2 51 112 Waiting: 21 51 15.1 50 111 Total: 56 137 45.4 143 251 Percentage of the requests served within a certain time (ms) 50% 143 66% 168 75% 175 80% 179 90% 193 95% 204 98% 221 99% 228 100% 251 (longest request)
核心指标,并发请求性能提升67%,延迟降低100ms
Requests per second: 165.78 [#/sec] (mean) Time per request: 241.288 [ms] (mean)
Requests per second: 276.95 [#/sec] (mean) Time per request: 144.430 [ms] (mean)
连接池配置修改之前,从13:34-13:53出现比较大的波动

修改配置之后10:35-10:38 波动较少
结论
连接池不宜设置过大的最大连接数,还需要配置连接尽快释放,可以提升并发能力,减轻应用更新时对数据库的影响
额外需要注意的点
实际上,连接池的大小的设置还是要结合实际的业务场景来说事。
比如说,你的系统同时混合了长事务和短事务,这时,根据上面的公式来计算就很难办了。正确的做法应该是创建两个连接池,一个服务于长事务,一个服务于"实时"查询,也就是短事务。
还有一种情况,比方说一个系统执行一个任务队列,业务上要求同一时间内只允许执行一定数量的任务,这时,我们就应该让并发任务数去适配连接池连接数,而不是连接数大小去适配并发任务数。
在更新了连接池配置后,发现发布时访问延迟波动还是比较明显

其中10:35分之后的波动,为更新了连接池配置的波动,还是比较大
10:34开始更新交易服务 10:40全部更新完毕
想起之前针对更新部署的优化,询问小马之前的说的eureka配置优化是否已经发布,小马表示已经上线
然而我去查看git历史,并没有合并入master的代码,查看构建系统,docker镜像,都没有更新过,上次更新还在2020年
小马表示不敢相信,最后确认代码还在本地,没有提交,他表示可能梦中发布了 :broken_heart:
于是提交代码,我进行测试发布
相关资料
在重新发布服务的时候,我们会先请求/pause端点,节点状态会变成DOWN,但是因为存在30秒的缓存,各个服务获取到的可用服务IP还存在延迟,导致ribbon把流量导到不可用的ip,然后进行多次重试,造成响应时间增加
更新eureka后,11:19分开始测试更新交易服务,响应延迟波动相比之前降低60%

结论
- 一级缓存不存在自动失效期和手动清除
- 二级缓存存在默认180s自动清除以及当注册服务下线,过期,注册,状态变更,都会来清除里面的数据
另外当二级缓存数据被清除以后以后,只能依靠定时任务刷新一级缓存里面的数据,也就是说最快也要等默认的30s才能更新一级缓存
- 一级缓存是默认开启的,如果不能忍受这30秒的响应缓存变更延迟,可以手动禁止使用一级缓存,然后把二级缓存改为你能忍受的时间
后续
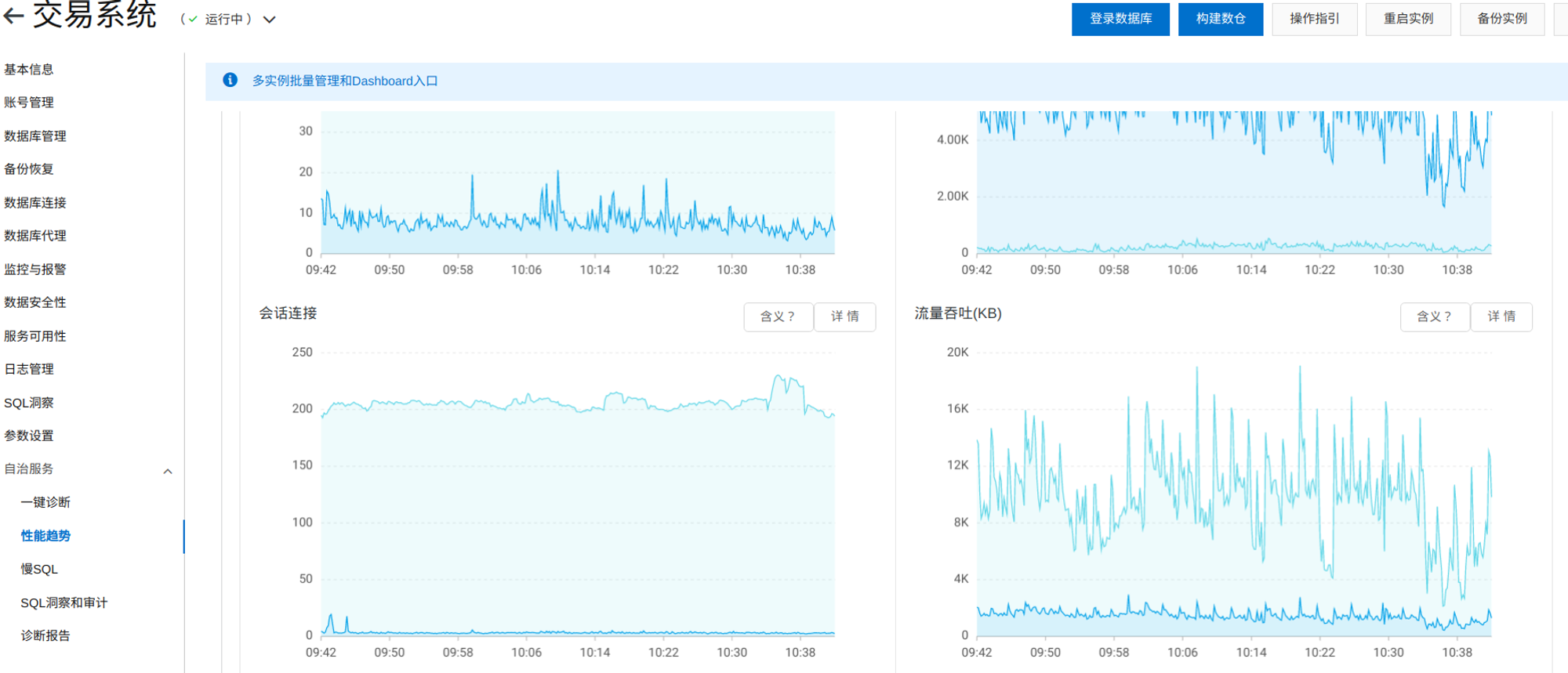
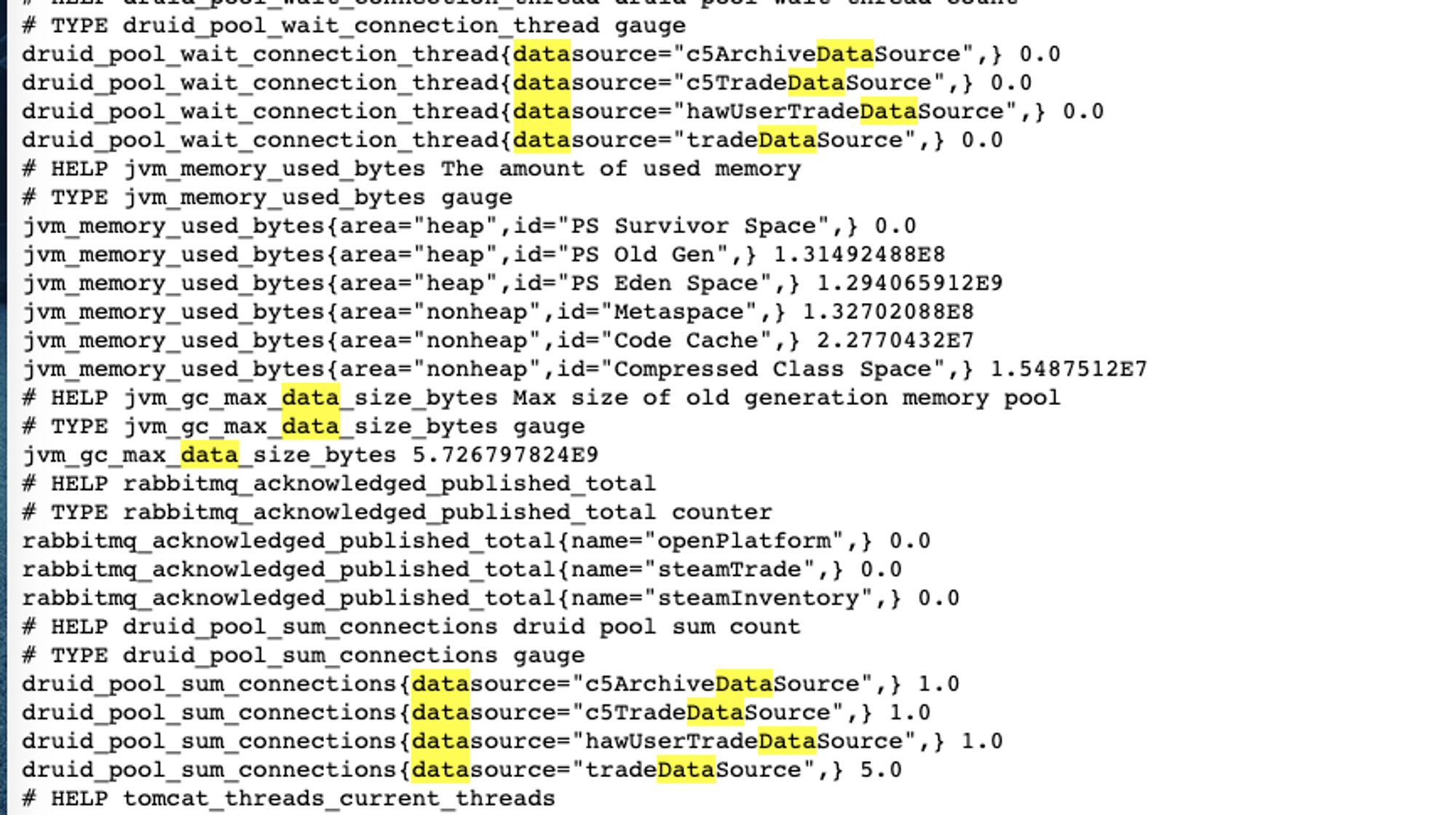
1.如何添加 druid 数据库连接池的监控指标
获取容器中所有类型为 DruidDataSource 的bean,然后遍历他们,map的key是这个 bean的id,也就是bean的名称,value 就是 DruidDataSource d对象,他身上可以获取到 活跃连接数
另外这是一个定时任务,即每个实例都会每三秒收集一次指标
@Component @Slf4j public class DruidDataSourceMetricsTask { private final static String ACTIVE_CONNECTIONS = "druid.pool.active_connections"; private final static String IDLE_CONNECTIONS = "druid.pool.pool_connections"; private final static String WAIT_CONNECTION_THREAD = "druid.pool.wait_connection_thread"; private final static String ACTIVE_PEEK = "druid.pool.active_peek"; @Resource private ApplicationContext applicationContext; @Resource private MeterRegistry meterRegistry; /** * 五秒收集一次连接池的指标 */ @Scheduled(fixedDelay = 3000) public void collectMetrics(){ Map<String, DruidDataSource> dataSourceMap = applicationContext.getBeansOfType(DruidDataSource.class); if (dataSourceMap.isEmpty()) { return; } for (String datasourceName : dataSourceMap.keySet()) { DruidDataSource druidDataSource = dataSourceMap.get(datasourceName); // 当前活跃连接数 Gauge.builder(ACTIVE_CONNECTIONS, druidDataSource::getActiveCount).tags("datasource", datasourceName).description("druid pool active count") .register(meterRegistry); // 当前连接池中的连接数 Gauge.builder(IDLE_CONNECTIONS, druidDataSource::getPoolingCount).tags("datasource", datasourceName).description("druid pool count") .register(meterRegistry); // 等待连接的线程数量,这个一旦大于0并且增多的话,就会导致对数据库的增删改查变慢,因为他需要等待一段时间才可以获取到连接才可以去操作数据库 Gauge.builder(WAIT_CONNECTION_THREAD, druidDataSource::getWaitThreadCount).tags("datasource", datasourceName).description("druid pool wait thread count") .register(meterRegistry); // 活跃峰值 Gauge.builder(ACTIVE_PEEK, druidDataSource::getActivePeak).tags("datasource", datasourceName).description("druid active peek") .register(meterRegistry); } } }
之后启动项目访问 /actuator/prometheus 端点,可以看到相应的指标数据。
2. 如何展示上述指标数据
例如,下图是 steamTrade 服务 以及 steamTrade 数据库中各实例的 活跃连接数的统计情况

3. 如何根据指标来对数据库链接池进行优化
这是我在胖子的基础上增大了最大连接数的修改,并且是以该数据发布的。 后面一张图是我调整后的配置
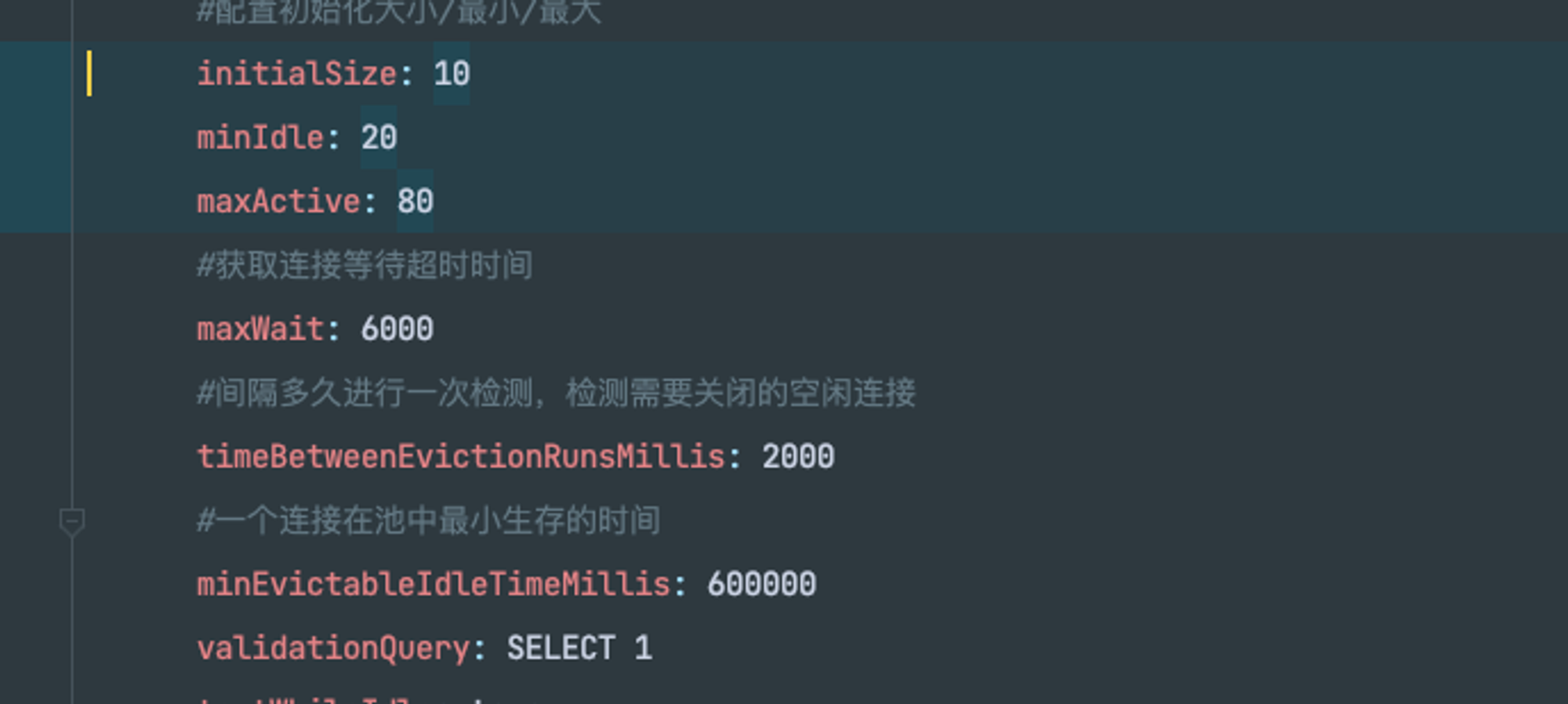

首先是初始连接数10个,在此基础上的发布,发布期间发现存在较多的线程存在需要等待才能获取连接的情况。所以初始连接数肯定是不够的,我后面把他改成了40个,可以发现后面发布的时候等待获取连接的线程数大大减少了。

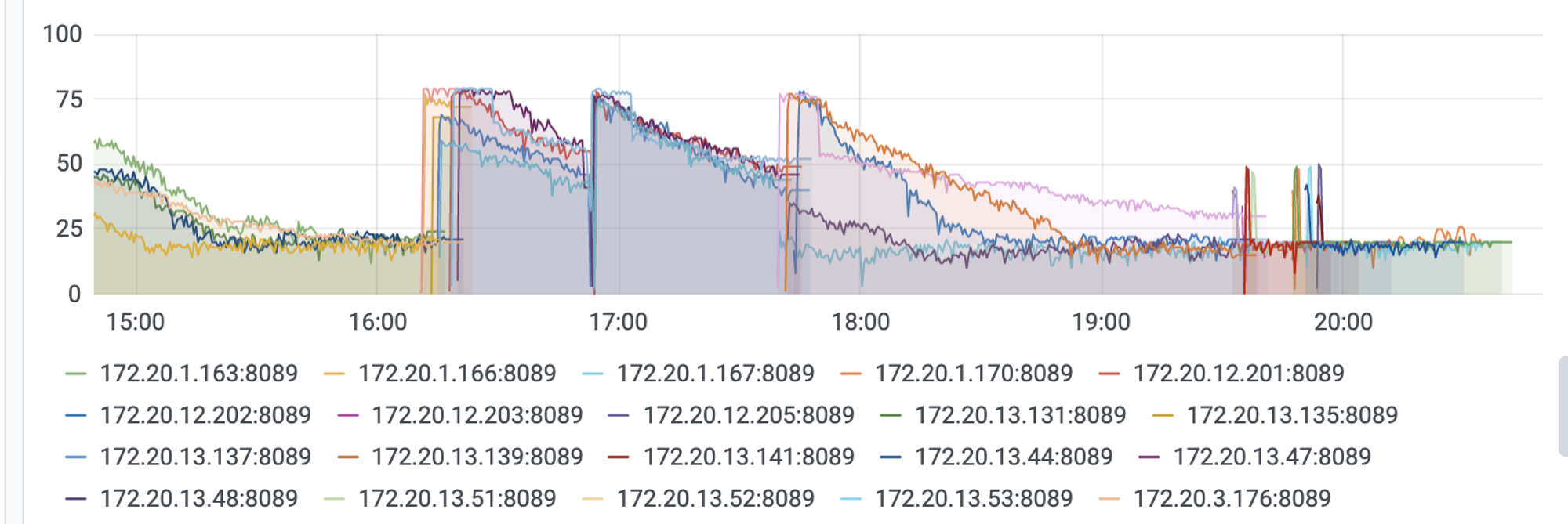
另外比较有问题的是 ,连接池中的连接数量,即空闲连接数量。(活跃的连接不在这之内)。
之前的策略是每2秒清理一次,最小空闲连接数量是10.但是可以看数据,即使2秒清理一次,我也从来没有看到空闲连接数量小于过20,这就表示,最小空闲连接数量10是肯定不够的。(因为被清理了后面程序需要又被新创建了。而这种不断清理创建连接资源的行为是非常的损耗性能的。)所以我觉得20这个数字是比较合适的最小空闲连接数量。可以看到20点之后这个数据非常的平稳维持在20左右。
另外还修改的一个参数是 minEvictableIdleTimeMillis 这个是一个连接最少的存活时间,相应其实还有一个最大的存活时间。原来的参数是 10分钟,我改成了1分钟。即当一开始应用起来会较多的创建连接,但是1分钟后这些多余的连接就会被清理回收掉。
总结:
像连接池线程池这种对象池化的思想其实非常常见。即最大程度的对对象(或者说是资源,像mysql的会话连接就是属于资源)进行复用,不用频繁的去创建和销毁对象,带来不必要的开销。
我所理解高性能的程序是:cpu将更多的时间用在程序本身逻辑上,而不是去做一些额外的工作。例如创建销毁对象,例如GC。
所以应该是去观察现有的业务情况下现有的指标是怎么样的,根据线上运行的程序再来合理的调整参数。这也是度量驱动开发的思想。
参考资料
致谢:
有任何问题,欢迎您在底部评论区留言,一起交流~